Здесь собираем предложения для ФИДЕ, но не обсуждаем их.
Обсуждение здесь.
Posts made by Bulldozer
-
Предложения для ФИДЕposted in ФИДЕ

-
RE: Видео полезные и не очень.posted in Разное
Как
торонтониане,торонтонианцы, торонтонцы (?) произносят название своего города.Спойлер:
сами не определились.https://www.facebook.com/torontostar/videos/10154478228326151/
-
RE: Движкиposted in Компьютеры
Сейчас понял, что задачи, где Стокфиш всех нагнул, имеют небольшое кол-во фигур. Примерно понятно - лучше перемалывает варианты, а в позиционных факторах менее силён.
-
RE: Движкиposted in Компьютеры
Внёс изменения в сравнительный тест движков/сеток на задачах Кошмар-2.
Добавлен Стокфиш. Он проиграл.
-
RE: Железо posted in Компьютеры
-
RE: Железоposted in Компьютеры
Всё больше убеждаюсь в том, что для Лилы пока не очень нужна крутая видюха типа RTX 2080Ti. Течёт память (которая системная RAM). У меня 32 GB, и она может утечь вся за час в зависимости от позиции. Ну, купишь ты 2080Ti вместо моей 2060 - так память кончится не за час, а за полчаса. Нужно тогда покупать 64 GB RAM как минимум.
Может быть пофиксят когда-нибудь, но жалобы уже давно, а воз и ныне там.
-
RE: Математические и логические задачиposted in Разное
Участник @xajik написал в Математические и логические задачи:
Добровольцам дали сразу
Только два для испытаний.
я понял, что каждому из добровольцев ( а их несколько) дали по 2 камня, те. камней не 2Если было бы так, то решение простое - 100 добровольцев - по 1 на каждый этаж и каждому по алмазу. Занимает ровно минуту.
-
RE: Математические и логические задачиposted in Разное
@xajik по условию алмаза ровно два. Можно разбить оба, но не больше.
-
RE: Математические и логические задачиposted in Разное
Спрашивается, сколько гномы пробудут максимум, если действуют оптимально.
Подразумеваем также, что гномы стараются минимизировать матожидание времени пребывания в доме.Определения
Назовём этаж плохим, если его номер не ниже номера уже проверенного этажа, с которого разбился алмаз.
Назовём этаж хорошим, если его номер не выше, чем наивысший уже проверенный этаж, с которого алмаз не разбился.
Назовём остальные этажи подозрительными - они выше всех хороших и ниже всех плохих.
Примечание: если первый алмаз ещё не кидался, то хороших или плохих этажей нет - все подозрительные.
Примечание: если первый алмаз разбился сразу, то хороших этажей нет - все или плохие (с какого разбился и выше), или подозрительные (ниже этажа, с какого разбился).
Примечание: если подозрительных этажей нет - это значит, что эксперимент закончился успешно (не значит оптимально) - гномы точно знают, где проходит граница между хорошими и плохими этажами. Если остались подозрительные этажи, это значит, что их задача не решена.Разобьём время пребывание гномов в доме на два этапа: первый этап длиной T1, когда они кидают первый алмаз и второй этап длиной T2, когда первый алмаз потрачен, и они кидают второй.
Если представить себе, что первый алмаз уже потрачен, то гномы обязаны, тут никуда не денешься, второй алмаз кидать с каждого подозрительного этажа по порядку, начиная с нижнего подозрительного (иначе есть вероятность потратить и второй алмаз, не получив точного ответа). В этом случае T2 равно максимум количеству оставшихся подозрительных этажей. Теперь задача гномов сводится к тому, чтобы оставить как можно меньше подозрительных этажей для второго этапа и в то же время не растягивать по времени первый этап.
Они могут на первом этапе, например, действовать методом дихотомии, а именно кинуть с 50-го этажа, потом с 75-го, потом с 87-го и т.д. Т.е., делить оставшийся отрезок примерно пополам. Не факт, что именно этот метод оптимален - нужно проверять. Допустим, мы знаем оптимальный метод для первого этапа. Тогда можно найти T1 как наиболее вероятное кол-во сделанных попыток до разбивания первого алмаза, а как найти T2 - см. выше. Останется сложить T1 и T2.
На самом деле я знаю, что есть неточность в рассуждениях выше - "оптимизировать" на самом деле нужно оба этапа одновременно.
Дальше я продолжать сейчас не буду, потому что нужно работать.
-
RE: Движкиposted in Компьютеры
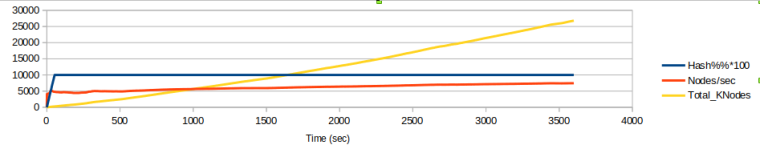
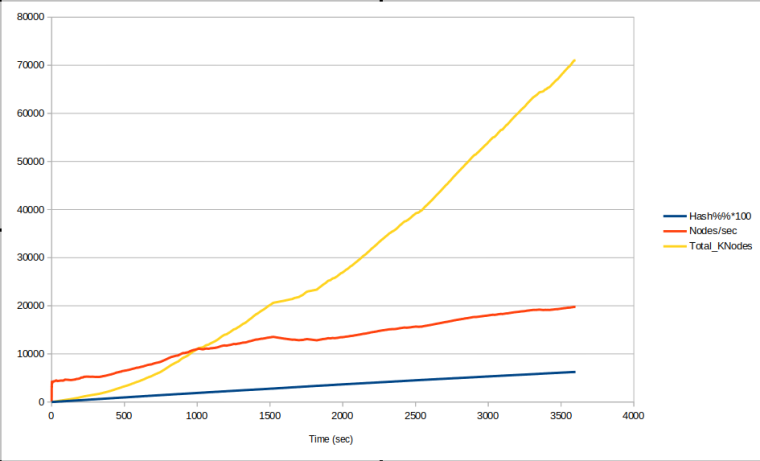
Две картинки о том, как важен параметр NNCacheSize в Лиле. Это размер кэша нейронной сети, выраженный в максимальном кол-ве сохраняемых позиций.
И почему его нельзя оставлять по умолчанию.В первом эксперименте NNCacheSize установлен по умолчанию (200K).
Во втором эксперименте он увеличен в 100 раз и равен 20M.В первом эксперименте кэш быстро заполнился (синяя линия), после чего скорость перебора позиций (красная линия) расти перестала, т.е., многие позиции идут на расчёт в видеокарту. Жёлтая линия - общее число просмотренных позиций - за час поднялась до 26K.
В втором эксперименте кэш даже к концу заполнился лишь на две трети (синяя линия). Скорость перебора позиций (красная линия) расти не переставала, т.е., многие позиции брались из кэша, а чем больше кэш, тем больше вероятность найти в нём позицию. Жёлтая линия - общее число просмотренных позиций - за час поднялась до 70K.
Вот так только настройкой кэша ускорили движок в 2.5 раза.
-
RE: Движкиposted in Компьютеры
Updated
Есть тесты Кошмар-2 (по наводке @Комс), которые якобы плохо решаются движками. Давайте посмотрим.
Прогнал эти тесты на четырёх движках: LC0 с тремя разными нейросетями и Stockfish 10.
Сетки, начинающиеся на J, больше по размеру, чем на T, и работают медленнее. Теоретически должны давать оценку лучше.
На решение отводилось 5 минут на каждую задачу. В таблице отмечено, кто решил или не решил соответствующие задачи. Если стоит смайлик, значит движок выбился из общей тенденции в хорошую либо плохую сторону.Position # LC0: T40B.4-260 LC0: J13-410 LC0: J13B.2-136 Stockfish 10 1 + + + - 
2 - - - - 3 - - - - 4 + + + + 5 + + + + 6 + + + + 7 + + + - 8 - - - - 9 + - + - 10 - - - - 11 - - + 
- 12 - - - + 13 - - - - 14 + + + + 15 - - - - 16 - - - + 17 + + + - 18 - - - - 19 - + + - 20 + + + + 21 - - - - 22 - - - - 23 - - - - 24 - - - + 25 + + + + 26 + + + + 27 + + + - 28 - - - - 29 + + + + 30 + + + - Sum 14 14 16 11 Победу одержала сеть J13B.2-136.
Примечания
Задачи эти надо ещё проверять. Далеко не во всех я уверен. Впрочем, это, наверное, не так важно.
Интересно будет ещё Стокфиш прогнать.Прогнал.Железо: RTX 2060 для LC0 и Core i7-9750H для Stockfish.
Для Stockfish включал 10 процессорных тредов из 12.
Подключены таблицы окончаний на SSD.
-
RE: Движкиposted in Компьютеры
Участник @комс написал в Движки:
поищи в инете тест "ночной кошмар II", не помню, как по-английски
Там есть даже поза из Полугаевский - Торре, 1982Или завтра скину
Но оболочка Фритц будет нужна, как ни крутиЗапустил в пакетном режиме (помнишь, для тебя делал? - пригодился) все 30 задач оттуда, по 7 минут на каждую. Когда отработает, проверю сколько правильных решений. Потом будем и другие сетки так проверять, и другие настройки.
-
RE: Движкиposted in Компьютеры
Мы пока сами попробуем покрутить. Будут конкретные вопросы - зададим.
-
RE: Движкиposted in Компьютеры
Пост, в общем-то, посвящается @Комс.
Меня не устраивает ширина поиска в Лиле и я играюсь с настройками с целью сделать так, чтобы слабые ходы получали больше времени.
В Лиле используется алгоритм UCT, и есть такая формула (1):
Cpuct' = Cpuct + CpuctFactor * ln((Nodes + CpuctBase)/CpuctBase)Это была основная формула. Можно, если нужно, выразить Nodes. Формула (2):
Nodes = CpuctBase * (e^((Cpuct' - Cpuct)/CpuctFactor) - 1)Или выразить CpuctBase. Формула (3):
CpuctBase = Nodes / (e^((Cpuct' - Cpuct)/CpuctFactor) - 1)Объясню формулу (1). Это всё конфигурационные параметры движка, кроме Cpuct' (это вычисляемый) и Nodes (сколько просмотрено узлов на данный момент при анализе ДАННОГО узла).
Из описания алгоритма известно, что баланс exploitation - exploration сдвигается вправо тем больше, чем больше Cpuct'. Т.е., чтобы поиск сделать шире, нужно увеличивать Cpuct', чего можно достичь увеличением Cpuct, или CpuctFactor, или уменьшением CpuctBase. И, само собой, при увеличении Nodes поиск расширяется автоматически.
Для каждого хода-кандидата вычисляется его приоритетность, а именно Cpuct' плюс некоторое слагаемое, с которым я особо не разбирался пока (оно зависит от оценки хода), и выбирается тот ход-кандидат, у которого сумма больше. Т.е., приоритетность хода-кандидата зависит от нодесов, просмотренных во время анализа этого хода ранее, от оценки хода и от конфигурационных параметров.По дефолту такие значения:
? = 3 + 2 * ln((Nodes + 19652)/19652)При дефолтных значениях динамика получается следующая.
Когда Nodes = 0 (т.е., свежий ход), то Cpuct' = 3.
Когда Nodes = 33K, то Cpuct' = 5.
и т.д., вот таблица:Nodes Time* Cpuct' 0 0 3 33K 3 sec 5 125K 12 sec 7 375K 37 sec 9 1M 100 sec 11 3M 5 min 13 8M 13 min 15 22M 37 min 17 59M 98 min 19 *Время указано на моей текущей конфигурации железа и софта. Может отличаться для разных видеокарт и нейросетей. Для справки: на RTX 2060 с нейросетью T40B.4-260 скорость расчёта примерно 10K nodes/sec = 600 Knodes/min = 36M nodes/hr.
Указано потраченное время только на обдумывание этого хода, но не других ходов-кандидатов.Если я держу движок уже 13 минут на ходе (причём, это означает общее время анализа уже намного больше, если этот ход не на первой линии!), то мне кажется, это значит, что я хочу уже широкого анализа, а не додрачивания оценки лучшего хода. Меня как-то не очень устраивает, что Cpuct' для 5 минут и 13 минут отличается так мало.Временно снимается - пока не понимаю полностью, как это всё работает.Можно крутить CpuctBase. Я ещё буду дописывать этот пост.
-
RE: Движкиposted in Компьютеры
Позиционные задачи никто же не мешает создать. Понятно, что они сложнее, но тем не менее.
-
RE: Движкиposted in Компьютеры
Есть ли какой набор тестов для движков, на котором можно сравнить разные движки, не устраивая никаких битв? Особенно это актуально для Лилы - так можно быстро сравнивать разные НН. Запустил на одной сети - задача решена за две минуты, на другой - за минуту. И уже понимаем, что вторая сеть лучше.
Только, получается, примеры нужны не простые, а хитрые - которые вот прям сразу не показывают правильный ход, а нужно подумать какое-то время. Навроде этюда ван Брекелена.
-
RE: Ферзевый гамбит (отказанный)posted in Дебют
Участник @camon14 написал в Ферзевый гамбит (отказанный):
но эта тема далеко не тухлая...
я имею ввиду, что ФГ лично для меня тухлая тема, я его не собираюсь играть черными ни за какие коврижки))
Я его играю чёрными только после 1. d4 Nf6 2. c4 e6 3. Nf3 d5. Новоиндийская - на любителя - там вообще центр сдаётся, Боголюбова тоже свои проблемы имеет. Поэтому пока так.
-
RE: Ферзевый гамбит (отказанный)posted in Дебют
Участник @комс написал в Ферзевый гамбит (отказанный):
у Корнева есть две книжки -- за белых с претензией на перевес..
Его анализ расходится с Лиловским довольно рано. Он рассматривает
Грубо говоря, он позволил прыгнуть коню на f3, и Лила это не очень поддерживает - сама-то она как-то заставляет белых делать такой манёвр: Nge2, Ng1, Nf3.") См. мой исходный пост.
См. мой исходный пост.
-
RE: Ферзевый гамбит (отказанный)posted in Дебют
Играю этот дебют за оба цвета и хочу тут немного копнуть с точки зрения Лилы.
И сразу шок.Ферзевый гамбит - может быть вовсе и не гамбит,
потому что оптимальная игра с самого начала не предусматривает быстрого d5. Этот ход делается немного позже, и тогда Лила уже не собирается отдавать пешку, а сразу меняется!
Подзаголовок - типа шутки.
Тем не менее, в этом посте хочу сосредоточиться именно на этом варианте.
Несколько следующих ходов обязательны, но могут быть сделаны с перестановками.
"Обязательные" ходы кончились, и здесь развилка с примерно равными оценками:
-
- Nge2 (+0.29)
-
- Qc2 (+0.28)
-
- Bg3 (+0.27).
9. Nge2: Конь идёт на e2, а потом передумывает и идёт на f3 через g1 с потерей темпов
9. Qc2: соглашаемся с разменом слонов
9. Bg3: слон убегает сам, чтобы отдаться более выгодно на e5
-
-
RE: Движкиposted in Компьютеры
Участник @комс написал в Движки:
это было реализовано в Гудини, насколько я помню...
его автор утверждал, что на экране не сантипешки, а вероятность победыНе вероятность победы, а ожидание набранного кол-ва очков в партии. Да, я знаю. Но не знаю, как реализовано - просто тупая масштабирующая формула или какие-то сложные изменения в оценочной ф-ии.
Пурга это всё, ИМХО
Не скажи. Реальный пример - Лила сейчас не попала в суперфинал, потому что слишком осторожно играла с лохами в круговом турнире. Если бы ей установить правильную цель типа "отчаянно бить лохов, а с фаворитами не рисковать", то такое могло бы не произойти. И тогда без вероятностей трёх исходов партии тут не обойтись - сантипешки не подойдут.
-
RE: Движкиposted in Компьютеры
Участник @комс написал в Движки:
Участник @bulldozer написал в Движки:
Во-первых, выходом оценочной функции позиции должны быть ТРИ числа: вероятности победы pw, ничьей pd и поражения pl. А не одно число - сантипешки, мегапешки или ещё что-то примитивное. Нужно три числа - по количеству результатов партии
во-первых, а сразу же и в последних, это только Лила может сделать, считая по методу Монте-Карло
Стокфишу на это насрать, он не знает статистики закончившихся партийЭто необязательно должно приходить из статистики сыгранных партий. Может использоваться и экспертный метод. Т.е., Стокфишу никто не мешает доработать оценочную функцию так, чтобы она оценивала вероятности победы, ничьей и поражения. Почему метод называется экспертным - потому что знания экспертов кладутся в основу формул оценочной ф-ии.
Понятно, конечно, что это будет менее точно, чем у Лилы.
-
RE: Движкиposted in Компьютеры
@bulldozer написал:
Разработчики движков недорабатывают. Если оценка небольшая и не увеличивается, то должна показываться ничья.
@комс написал :
как бы реализовать векторное развитие движков?
Шоб эти гады считали в основном линии, в которых оценка растёт, пусть она изначально и меньше в искомой позе...Динамический движок
Нужно полностью пересмотреть подход к результатам работы движка, потому что это тесно связанные вещи.
Стокфиш - самый примитивный движок. Насколько понимаю, его вывод - это просто выход его оценочной функции в сантипешках. У Лилы чуть поинтеллектуальнее, но всё равно не то.
Мой подход следующий.Во-первых, выходом оценочной функции позиции должны быть ТРИ числа: вероятности победы pw, ничьей pd и поражения pl. А не одно число - сантипешки, мегапешки или ещё что-то примитивное. Нужно три числа - по количеству результатов партии, согласно правилам игры в шахматы!
Во-вторых, перед началом работы движка мы должны обозначить ЦЕЛЬ. По умолчанию цель - максимизировать количество набранных очков (1 - победа, 0.5 - ничья, 0 - поражение). Но цель может быть другой. Например, та же максимизация, но правила набирания очков отличны, например, 3 - победа, 1 - ничья, 0 - поражение. Или 9 - победа белыми, 10 - победа чёрными и т.д.
Цель может быть различной для разных турнирных или матчевых ситуаций или при игре по отличающимся правилам. Бывает так, например, что нас устраивает только победа. И других ситуаций много можно придумать.
Сейчас же цель движку ставится одна и та же всегда, а именно такая: найти ход, которые даёт оптимальный (в смысле минимакса) для обоих игроков рез-т оценочной ф-и. И это, увы, совсем не то, что нужно в реальной жизни.
Цель движку будет задаваться простой формулой: тремя коэффициентами, на которые он будет умножать вероятность победы pw, ничьи pd и поражения pl, суммировать их и максимизировать. Например,
{ 2x, x, 0 } - дефолтный набор к-тов. Соответствует максимизации ожидаемого рез-та при стандартном начислении очков (1 - 0.5 - 0)
{ x, 0, 0 } - если нас устраивает только победа
{ x, x, 0 } - если нас в равной степени устраивает победа или ничьяНапример, если нам нужно выигрывать, но ничья не совсем плохой результат, то мы можем выбрать такую цель движку: { 0.8, 0.2, 0.0 }.
И, допустим, возникло две позиции, которые движку нужно сравнить, чтобы понять, какая лучше:
а) { pw = 0.2, pd = 0.6; pl = 0.2 }
б) { pw = 0.3, pd = 0.4; pl = 0.3 }
У них равные мат.ожидания результата по стандартным правилам. Т.е., в обычной ситуации движок мог бы пойти на любую из них, потому что ему пофиг на результативность - главное, чтобы мат.ожидание было лучше. А тут МО одинаковы. Но нам нужна победа, и мы задавали соответствующую цель. И движок должен выбрать вариант б, потому что0.3*0.8 + 0.4*0.2 + 0.3*0.0 = 0.32больше, чем0.2*0.8 + 0.6*0.2 + 0.2*0.0 = 0.28.Вот после того, как это будет реализовано, возможно появление "в-третьих", а именно то, что написал @Комс, и об этом см. ниже.
В-третьих, на самом деле в вычислениях чуть выше должен использоваться не вектор { pw, pd, pl }, а вектор, который назовём { Pw, Pd, Pl }. Большими буквами я символизирую, что вероятности эти - не просто из оценочной фунции, а из дополнительной оценочной ф-ии, которая является надстройкой над существующей "примитивной". Т.е., окончательный вывод движка берётся из оценочной ф-ии, которая принимает во внимание динамическое изменение оценки позиции во времени - через каждые несколько секунд анализа изменения оценки фиксируются и положительная динамика даёт положительную коррекцию оценке.
Почему я увязал создание динамического движка с переходом на три числа вместо одного в оценке - потому что указанная надстройка над "примитивной" оценочной функцией наверняка потребует на вход полный набор вероятностей, а не абстрактные сантипешки, которые мало что говорят об ожидаемой частоте соотношения побед/ничьих и никак не учитывают нашу цель в партии. Во всяком случае, мне так кажется.
